

Ponieważ ludzkość od niepamiętnych czasów (a przynajmniej od czasów Darwina i Mendelejewa) lubi klasyfikować, również dla metadanych uruchomiono proces „szufladkowania”. W zależności od miejsca i systemu wykorzystującego metadane znajdziemy takich klasyfikacji całkiem sporo. Spotkacie się z podziałem na metadane: administracyjne, opisowe i strukturalne. Albo też na biznesowe i techniczne. A także z wieloma innymi podziałami.
Przyznam się jednak szczerze, że gdy chciałem podzielić metadane (inaczej dane referencyjne) hurtowni danych według powyższych kategorii zawsze coś mi zgrzytało. Czy tabela słownikowa opisująca kod produktu występujący w tabeli głównej to będą dane opisowe (w końcu opisuje wielkość biznesową) czy strukturalne (w końcu jest relacja pomiędzy kluczem głównym i obcym)? Drugi podział nastręczył mi jeszcze więcej problemów. Czy reguła opisująca sposób transformacji danych (np. podział na segmenty klientów wg liczby i wartości ich transakcji z firmą) to są dane biznesowe (w końcu definicję stworzył biznes) czy też techniczne (bo przecież są to mapowania procesów ETL)?
Pozostawiłem więc do dyskursów akademickich szufladkowanie metadanych i uznałem, że znacznie ważniejsze jest określenie które metadane są najistotniejsze z punktu widzenia osób zarządzających hurtownią danych czy też systemem baz danych, jak i osób z niej korzystających.
Poniżej spisałem moją subiektywną listę ważnych metadanych w tych systemach:
- metadane bazy danych,
- tabele referencyjne,
- metadane procesów ETL i DQM,
- logi przetwarzań,
- logi i statystyki dostępu do danych.
Nie twierdzę, że wymieniłem wszystkie dane referencyjne. Moją intencją było jednak zwrócenie uwagi na te, które pomagają nam zrozumieć i zarządzać informacją.
Metadane bazy danych
Same bazy danych dostarczają nam bogatych informacji o danych bez uruchamiania zapytań na tabelach z tymi danymi.
Struktury tabel i obiektów bazodanowych
Możemy sprawdzić dzięki temu typy i długości pól w tabelach, ich opisy a nawet statystyki dotyczące zawartości pól. Ograniczę się tutaj do dwóch najpopularniejszych silników bazodanowych czyli SQL Servera oraz Oracle.
SQL Server, powszechnie używany silnik bazodanowy, posiada szereg widoków w schemacie sys dla każdej bazy danych. Łącząc te widoki po kluczu OBJECT_ID jesteśmy w stanie wyciągnąć wiele informacji zarówno o tabelach, jak i o polach w tabelach.
Jeszcze łatwiejszy jest dostęp do struktury tabel poprzez tzw. INFORMATION_SCHEMA. Np. poniższe zapytanie wyświetli nam komplet informacji o strukturze tabeli CUSTOMER:
select * from INFORMATION_SCHEMA.COLUMNS
where table_name=’CUSTOMER’
Dostęp do metadanych w bazie Oracle jest równie łatwy. Wystarczy sięgnąć do widoków z prefiksem ALL_. Analogiczne zapytanie wyciągające informacje o strukturze tabeli CUSTOMER będzie wyglądać następująco:
select * from ALL_TAB_COLUMNS
where table_name=’CUSTOMER’
Opisy tabel i pól
W obu bazach można również przechowywać opisy do tabel i do kolumn. W tym przypadku ważne jest, aby takie opisy wprowadzać na etapie tworzenia struktur bazy danych. W silniku SQL server do trzymania opisów służy obiekt sys.extended_properties, gdzie w polu VALUE mogą być przechowywane opisy do pól, jak i tabel (MAJOR_ID jest kluczem tabeli, a MINOR_ID kluczem pola). Dla bazy Oracle trzeba skorzystać z widoków ALL_TAB_COMMENTS lub ALL_COL_COMMENTS.
Statystyki bazy danych
Równie ważna, jak powyższe dane, jest informacja o statystykach tabel i pól. Statystyki zostały stworzone dla optymalizatora zapytań i budowania sensownych planów zapytań. Ale dzięki nim możemy również zobaczyć rozkład wartości w poszczególnych polach oraz poziom ich wypełnienia.
Role dostępu bazy danych
Przy dużej liczbie użytkowników końcowych hurtowni czy bazy danych uprawnienia nadajemy przez role LDAP. Informacje o tym, jakie role są przypisane do poszczególnych elementów bazy (tabele, widoki) również zawarte są w metadanych tej bazy. Poniżej przykład raportu jaki moglibyśmy wykonać na pojedynczym polu DATE_RAP tabeli CUSTOMER bez dostępu do samych danych.
Analizowana kolumna: CUSTOMER.DATE_RAP [Data raportowa danych]
Uprawnienia do tabeli (role LDAP)
Tab. 1

Informacje o tabeli (statystyki):
Tab. 2

Informacje o polu (statystyki):
Tab. 3
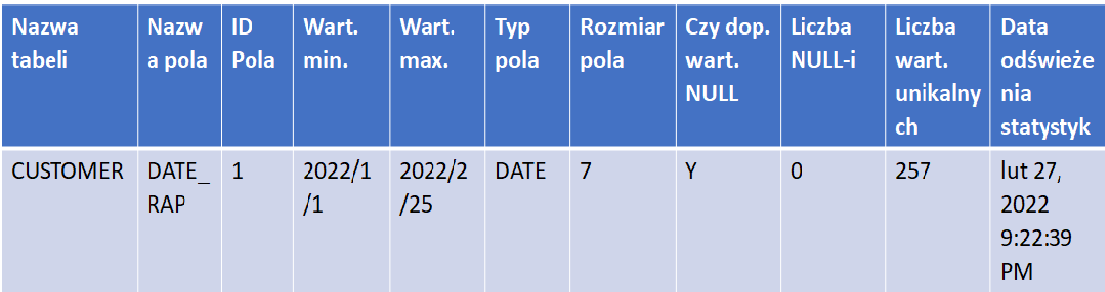
Już na podstawie powyższego potencjalny użytkownik może stwierdzić czy dana tabela i jej pola są dla niego interesujące z punktu widzenia jego projektu czy raportu. Jeśli tak, na podstawie informacji o roli LDAP będzie wiedział o co wystąpić, aby móc z tabeli czytać dane. Do przechowywania tych informacji nie potrzebujemy żadnych narzędzi poza tym, co oferuje sam silnik bazodanowy.
Tabele referencyjne
Tabele referencyjne to najczęściej słowniki opisujące różnego rodzaju kody występujące w naszej bazie danych. Np. w tabeli zawierającej transakcje sprzedanych aut w salonie nie musimy wpisywać informacji o marce i modelu auta. Wystarczy, że umieścimy tam odpowiedni kod, np. we wtorek sprzedaliśmy 12 samochodów o kodzie F12 oraz 7 samochodów o kodzie D05. W tabeli słownikowej przechowujemy opis tych kodów tak jak poniżej:
Tab. 4

Jak widać jeden kod może być opisywany przez cały szereg atrybutów tłumaczących o jaki rodzaj auta chodzi. Inne dane pojazdu – dotyczące roku produkcji, ceny – będą znajdowały się w tabeli zawierającej informacje o konkretnym egzemplarzu samochodu, gdzie kluczem głównym może być np. numer podwozia.
Ale tabele referencyjne to nie muszą być proste słowniki. Równie dobrze może być to struktura hierarchiczna utrzymywana w modelu parent-child lub w modelu tabeli płaskiej, w której kolejne kolumny stanowią poziomy hierarchii. Przykład implementacji takich hierarchii poniżej:
Struktura hierarchii parent-child
Tab. 5

Struktura hierarchii płaskiej
Tab. 6

Generalnie temat ujmując, tabele referencyjne będą przechowywały klucze główne obiektów, których referencje będą występowały (w postaci kluczy obcych) w innych tabelach oraz opisy tych obiektów. Część takich referencyjnych tabel jesteśmy w stanie pozyskać z systemów źródłowych, jak np. ERP. Ale przy przetwarzaniu hurtowni danych mogą być tworzone nowe pojęcia biznesowe, dla których trzeba tworzyć kolejne tabele referencyjne (segmenty klientów, hierarchie produktów, typy transakcji itp.) wówczas będziemy potrzebowali narzędzia wspomagającego zarządzanie metadanymi.
Większość narzędzi ETL ma różnego rodzaju dodatki wspierające zarządzanie metadanymi. Niestety często mają wąskie zastosowania i pomagają przy budowie modelu albo przy migracji procesów ETL. Do bardziej uniwersalnego zastosowania trzeba skorzystać z narzędzi niezależnych dostawców.
Metadane procesów ETL i DQM
Dotykamy tutaj obszaru szerokiego, jak wody Dunaju. O samych metadanych ETL można by napisać książkę. To one zawierają opis wszystkich algorytmów i procesów transformacji danych. Bo przecież mamy scenariusze przetwarzań zawierające powiązania pomiędzy poszczególnymi zadaniami. Dodatkowo scenariusze mogą mieć swoje podscenariusze i nadscenariusze a więc dochodzi nam struktura hierarchiczna. Mamy dla scenariuszy stworzone wyzwalacze które określają kiedy mają być one uruchomione. Każde zadanie w scenariuszu to kolejne metadane generujące kod, który przelicza dane. Narzędzia ETL mogą dodatkowo materializować wykonane już scenariusze i przechowywać ich historyczne drzewa przetwarzań.
Na szczęście zarządzaniem powyższymi elementami zapewniają nam same narzędzia ETL. Z naszej strony powinniśmy tylko zadbać aby był łatwy dostęp do tych metadanych chociażby po to aby sprawdzić jaka jest ścieżka krytyczna naszych przetwarzań lub zbudować prosty kokpit przetwarzań dla użytkowników biznesowych.
W przypadku procesów DQM (Data Quality Management) występuje znaczne podobieństwo do procesów ETL. Również mamy wyzwalacze, również możemy budować ścieżki przetwarzań (selekcje, joiny, agregacje) aby na końcu sprawdzić poprawność danych. I również zarządzanie nimi zapewniają same narzędzia DQM.
Reguły przetwarzań i jakości danych
Zatrzymajmy się teraz na sercu metadanych ETL i DQM czyli regułach przetwarzań i jakości danych. Tutaj nie zawsze mamy wsparcie narzędzi do swobodnego tworzenia i zarządzania regułami. Często zarówno w przypadku ETL, jak i DQM, mamy zestaw gotowych bloczków (odpowiedników zadań) i wpisywanie w nie reguł jest żmudne i czasochłonne. Zwykle też implementacja takich reguł zaczyna się w biznesie, który tworzy opis merytoryczny reguły, którą następnie na kod zamienia programista ETL.
Wyobraźmy sobie regułę, która dzieli klientów na klientów „złotych” i „zwykłych” w zależności od wielkości transakcji wykonanych z klientem w ostatnim roku. Reguła wyglądałaby mniej więcej tak: Jeżeli typ klienta jest „Indywidualny” oraz suma transakcji w ostatnim roku była większa niż 20 tys. PLN to klient jest „złoty” w przeciwnym razie „zwykły”. Jeżeli typ klienta jest „Firmowy” oraz suma transakcji w ostatnim roku była większa niż 100 tys. PLN to klient jest „złoty” w przeciwnym razie „zwykły”.
Dopóki reguła jest w miarę niezmienna możemy w narzędziach BI uruchamiać różnego rodzaju raporty typu data lineage czy impact analysis i dowiedzieć się w jaki sposób były wyliczone nasze wielkości biznesowe.
A co się stanie, jeśli któregoś dnia zmienimy nasze reguły i wprowadzimy do narzędzia ETL nowe? Przykładowo: Jeżeli typ klienta jest „Indywidualny” oraz suma transakcji w ostatnim kwartale była większa niż 10 tys. PLN to klient jest „złoty” w przeciwnym razie „zwykły”. Jeżeli typ klienta jest „Firmowy” oraz suma transakcji w ostatnim kwartale była większa niż 50 tys. PLN to klient jest „złoty” w przeciwnym razie „zwykły”.
Czy jeśli zmianę przeprowadzimy w czerwcu to będziemy w stanie wykonać data lineage dla wyliczonych danych w styczniu lub w lutym?
Bez historyzacji reguł (a tego najczęściej narzędzia ETL nie dostarczają) dostaniemy błędną odpowiedź.
I tutaj znowu kłania się narzędzie wspomagające zarządzaniem metadanymi, w którym warto przechowywać kolejne wersje reguł ETL wraz z informacją kiedy reguła była zmieniona oraz kto wprowadził zmiany. Procesy ETL powinny natomiast sięgać do repozytorium reguł i w zależności od tego jaką datę raportową przetwarzamy skorzystać z odpowiedniej wersji reguły.
Poniżej przykład jak taka reguła mogłaby wyglądać w naszym repozytorium:
Tab. 7

Teoretycznie nic nie stałoby na przeszkodzie aby taki słownik reguł przekazać do utrzymania w biznesie. Musielibyśmy mieć jednak pewność, że narzędzie wspomagające zarządzaniem metadanymi będzie potrafiło walidować składnię reguł przetwarzania. W przeciwnym wypadku zwykły czeski błąd, np. gdy zamiast WHEN napiszemy WHNE, spowoduje błędy i zatrzymanie całego scenariusza przetwarzań.
Logi przetwarzań
Pliki czy tabele logujące z jednej strony zawierają informację o pewnych wydarzeniach, więc można je traktować jako dane. Z drugiej strony podczas gdy metadane ETL opisują sposób przetwarzań, logi opisują zdarzenia kolejnych etapów przetwarzań, które prowadzą do powstania właściwych danych, więc możemy je uznać za metadane.
Większość narzędzi ETL udostępnia logi przetwarzań. Niestety nie zawsze te logi przechowywane są w tabelach relacyjnych. Często są to pliki tekstowe zawierające bogate opisy, jakie procesy w danym zadaniu zostały uruchomione, natomiast brakuje łatwo dostępnej informacji dot. tego kiedy zadanie zostało uruchomione i kiedy zostało zakończone.
A przecież na relacyjnych tabelach zawierających informacje dot. godzin rozpoczęcia i zakończenia zadań i scenariuszy można zbudować kokpity przetwarzań czytelne nie tylko dla administratora procesów ETL, ale również dla użytkownika z biznesu, który czeka na końcowe dane potrzebne mu do raportowania. Dodatkowo przechowując historyczne logi przetwarzań można wyliczać średnie czasy przetwarzań dla zadań i scenariuszy i na tej podstawie prognozować daty zakończenia przetwarzań co ma ogromną wartość biznesową.
Popatrzmy na przykład takiego prostego kokpitu, który składa się z 5 grup zadań (użytkownik z biznesu nie musi oglądać setek zadań składających się na scenariusz przetwarzania):
Tab. 8

Mamy też pracownika, który musi dzisiaj przygotować raporty w oparciu o kostki wielowymiarowe. Pracownik widząc na zegarze godzinę 15-tą, oraz prognozy powyższego kokpitu może przerwać pracę i wrócić do niej ok. 19:30.
Nawet jeśli po drodze wydarzy się awaria i jej usunięcie zajmie ok. godzinę to o godzinie 19.30 pracownik co najwyżej zobaczy zaktualizowaną prognozę końca zadań:
Tab. 9

Brak mechanizmu odkładania logów w odpowiedniej strukturze w narzędziu ETL można łatwo naprawić. Wystarczy pomiędzy zadaniami scenariusza dołożyć bloczki, które będą wstawiały rekordy z odpowiednimi informacjami (data sprawozdawcza, nazwa zadania, flaga START/STOP, godzina i data) do nowej tabeli logującej.
Logi i statystyki dostępu do danych
Uruchamiając odpowiedni poziom audytu bazy danych możemy dowiedzieć się kto i kiedy sięgał do tabel naszej bazy czy hurtowni. Agregując następnie te informację dostaniemy bardzo przydatne statystyki, które pokażą nam które dane są częściej i powszechniej używane, a więc bardziej krytyczne dla użytkowników biznesowych. To bezcenne źródło informacji pod optymalizację przetwarzań oraz zmianę ścieżki krytycznej przetwarzań (przeliczamy i optymalizujemy najpierw te dane, które są bardziej przydatne dla biznesu). Statystyki w znacznym stopniu mogą też ułatwić prowadzenie właściwej polityki retencji danych.
Również w przypadku RODO łatwiej będziemy w stanie spełnić jego wymogi (nakładające na nas obowiązek ochrony danych osobowych i wrażliwych) gdyż logi dostępu do danych pomogą nam zarządzać ryzykiem wycieku informacji z naszej bazy.
Podsumowanie
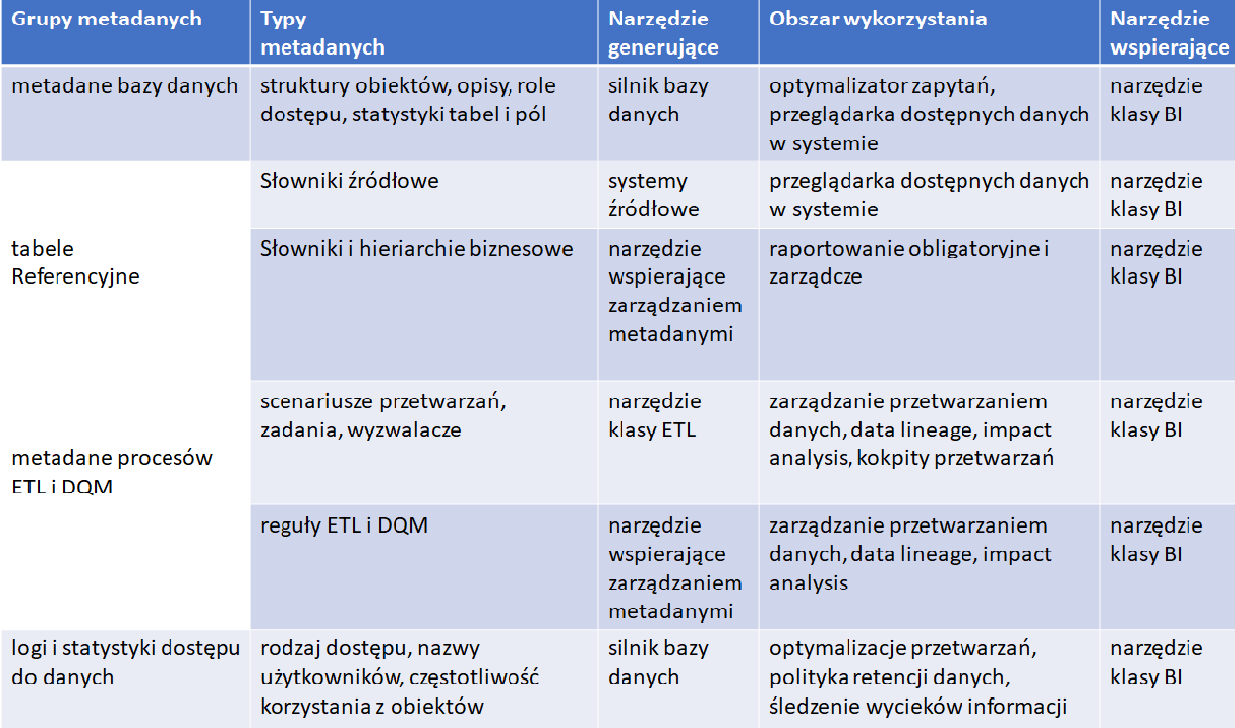
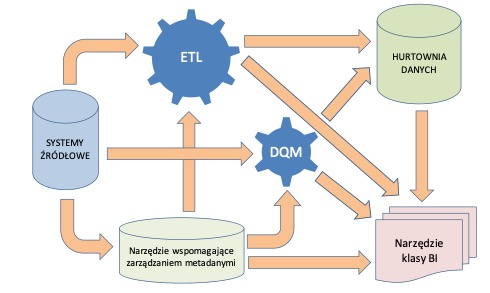
Metadane pozwalają nam rozumieć dane i lepiej nimi zarządzać. Skupiać uwagę powinniśmy przede wszystkich jednak na tych danych referencyjnych, które wprowadzają dodatkową wartość biznesową do naszych systemów baz danych i hurtowni danych. Poniżej przedstawiam główne tezy artykułu w postaci tabelki (a jednak nie obyło się bez „szufladkowania” 🙂 ) i schematu przepływu metadanych.
Zdzisław Dec, architekt rozwiązań hurtowni danych w Banku BNP Paribas
Tab. 10
Artykuł ukazał się w numerze 2 (93) /20200 magazyny IT Wizz. Publikacja za zgodą wydawnictwa oraz autora.


