

The classic approach to ETL process design, in which the entire process is implemented in the tool, has undeniable advantages:
- We manage the entire processing from a single tool
- We can easily prepare process documentation
- We can trace data flows within processes.
However, when the complexity of the processes starts to grow significantly, all these advantages cease to be beneficial. Instead of an originally readable data flow diagram in the process, like the one below:
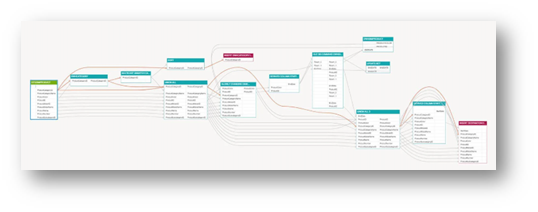
We get a completely unreadable and unusable scheme:
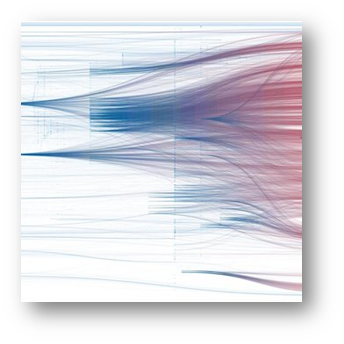
Moreover, there are other disadvantages of such an approach:
- Changing the way the process works requires introducing it directly in the ETL tool
- Changes can only be made by people who: have access to the ETL tool, know how it works, and have the appropriate technical knowledge.
So, how can we fix this?
I have often written that using dictionaries to parameterize data processing processes (e.g., when populating data warehouses) is an effective way to solve problems related to the ongoing adaptation of these processes to the changing business environment. In my many years of practice gained while implementing projects related to building data warehouses or implementing reporting systems, I have found that this type of approach has its advantages, which make me prefer it over others.
If we prepare the data processing process in such a way that the entire business definition – for example, mapping input data to output structures – is transferred to an external dictionary in the form of a database table, we will significantly increase the flexibility of such a process. Well, we have moved the mapping definition outside the ETL tool. What’s next? We have improved the readability of such a process, and we can change its shape by changing the mapping definitions without having to use the ETL tool interface.
Does this make more sense?
The answer will be “definitely yes” if we use Metastudio DRM to manage such a dictionary. Why? Namely, for columns where mapping definitions are stored – these are usually fragments of code in the syntax of languages such as SQL or 4GL – we can define syntax validation. The syntax validator allows you to first check the correctness in terms of formalities: built-in functions, logical operators, arithmetic operators, etc. However, the mentioned code fragments often use strings such as table and column names, custom function names, procedures, or finally defined constants. To be absolutely sure that the introduced code fragment will be correctly interpreted in the ETL server’s runtime environment, we can additionally enrich the syntax validator definition with:
- a list of correct constants, e.g., names of objects (columns) that can be used
- a list of custom function names, along with the correct number and format of parameters
- a list of variable names.
Thanks to the above, it will be possible to make such a dictionary available for maintenance by business users who do not have access to the ETL tool, and cannot independently test whether the processing based on this dictionary will be performed correctly. In the meantime, the syntax validation functionality will allow you to achieve the desired effect – the user responsible for updating such a dictionary will already be informed at the editing stage whether the changes made by him are correct.


